Bielefeld Center for Data Science
Hier kommt noch Text hin

Interdisciplinarity at BiCDaS


In a modern world, each discipline has to deal with different types of data, and a given type of data can occur in a variety of disciplines. Neuroscientists, for instance, frequently deal with image data and digital signals but rarely deal with finance data.
On the other hand, radio telescopes in astronomy generate digital signals that can be described using the same fundamental terms as EEG data in neuroscience, and dynamic systems in economics can be studied with methods that have already proven beneficial in physics. It is at the heart of Data Science that data is not treated as a local phenomenon by each discipline individually but as an interdisciplinary field of research, teaching, and knowledge.


If data is not to be treated as a local phenomenon, academics need to learn what data exists in other disciplines, how it is handled, and what parallels exist; generally, they need to learn from one another.
This strongly interdisciplinary approach will yield a fruitful exchange of methods, models and theories. Therefore, interdisciplinarity is a key strength and basic philosophy of BiCDaS. An agile, data-centred exchange format making use of the data-induced affordance towards interdisciplinarity are the so called DataLabs.
We identified four broad types of data, we believe, capture the vast majority of scientific data: graphs/networks, images, time series/signals and text:

© Nils Hachmeister Image Data
Image data is common in many different scientific disciplines, ranging from medicine to robotics to history. The term "image" is very broad here, including volume depiction (3D images) and even temporal sequences (movies).

© mrspopman - stock.adobe.com Network
Graphs nor networks, i.e., data which can be understood as a collection of vertices and edges, have become more and more common recently, and methods for analyses of large graphs have become much more sophisticated. Data of this type comes from many different scientific disciplines, including neural and social networks and co-occurrence graphs on text.
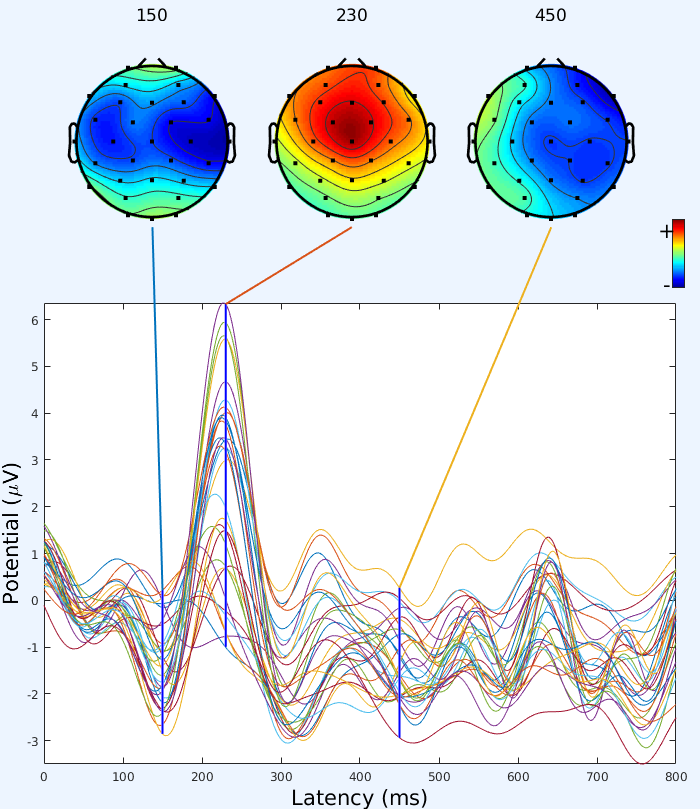
© Nils Hachmeister Digital Signals
Time series data or signals, with data points measured over time, are not only common in MINT sciences, but they are also very important in economics, social sciences and more.

© JethroT – stock.adobe.com Text Corpora
Text analysis treats written word as a type of data (meta-level). Common types of analyses are co-occurrence or word count. These types of analyses are found in all of the humanities, legal science and more.