Generative KI-Werkzeuge
Hintergründe und Informationen zum Einsatz generativer KI-Werkzeuge in Studium und Lehre

Generative KI-Werkzeuge in Studium und Lehre

Dr. Benjamin Angerer
Digitales Lehren und Lernen in der Hochschuldidaktik
- Telefon
- +49 521 106-87940
- Raum
- UHG A2-118
Die aktuelle Handreichung zum Umgang mit generativen KI-Werkzeugen an der Universität Bielefeld des Prorektorats Studium und Lehre (Stand: Juli 2024) finden Sie hier.
Hinweis: Besuchen Sie unseren Moodle-Selbstlernkurs "Generative KI in Studium und Lehre" für Studierende und Lehrende! Hier werden ohne technische Voraussetzungen in knapp 90 Minuten Bearbeitungszeit die wesentlichen Hintergründe, Möglichkeiten und Regelungen zusammenfasst.
Auf dieser Seite fassen wir für Sie hochschuldidaktische und weiterführende Informationen zum Themenbereich generative KI in Studium und Lehre zusammen. Ohne tief in technische Details abzutauchen, erfahren Sie hier in Kürze, was Sie über diese Technologie, ihre Grenzen und Auswirkungen wissen sollten. Darüber hinaus geben wir Ihnen Empfehlungen und Inhalte an die Hand, um
- generative KI als Lehrgegenstand in Ihren Veranstaltungen zu behandeln (z.B. im Rahmen eines Dialogs mit Ihren Studierenden über Fragen guter wissenschaftlicher Praxis oder der Hilfsmittelzulässigkeit) und um
- für sich die Frage zu beantworten, ob Sie generative KI-Werkzeuge in Ihrer Lehre bzw. in Ihrem Studium einsetzen wollen - und falls ja, wie und wozu.
Ein zentraler Hinweis dazu vorneweg: Aufgrund der Funktionsweise generativer KI-Systeme müssen alle Ausgaben von darauf basierenden Werkzeugen von ihren Nutzer*innen immer auf Richtigkeit und Angemessenheit geprüft werden. Sollten Sie dazu im Rahmen einer vorliegenden Aufgabe nicht in der Lage sein (weil Ihnen z.B. die Zeit oder der nötige fachliche Hintergrund fehlt), raten wir vom Einsatz generativer KI-Systeme für diesen Zweck ab.
In anderen Fällen bietet es sich an, durch eigene Versuche Erfahrungen zu gewinnen, um einschätzen zu können, ob der Einsatz generativer KI-Systeme für einen individuellen Anwendungsfall lohnenswert ist oder nicht.
Um solche und auch zahlreiche andere Experimente zu ermöglichen, stellt die Universität Bielefeld ihren wissenschaftlichen Mitarbeitenden und Studierenden ab dem 1. Oktober 2024 das „Bielefelder KI-Interface“ (kurz: BIKI) zur Verfügung. BIKI erlaubt es, Sprachmodelle von OpenAI sowie einige von der GWDG betriebene Open-Source-Sprachmodelle direkt über die Uni-Webseite zu benutzen. Das hat den Vorteil, dass Sie sich bei keinem externen Dienstleister registrieren müssen und keine individuellen Kosten für Sie entstehen.
Prof. Benjamin Paaßen hat zu BIKI verschiedene Videos erstellt und gibt Hinweise für die verantwortungsvolle Nutzung.

Hintergrund
- Technik
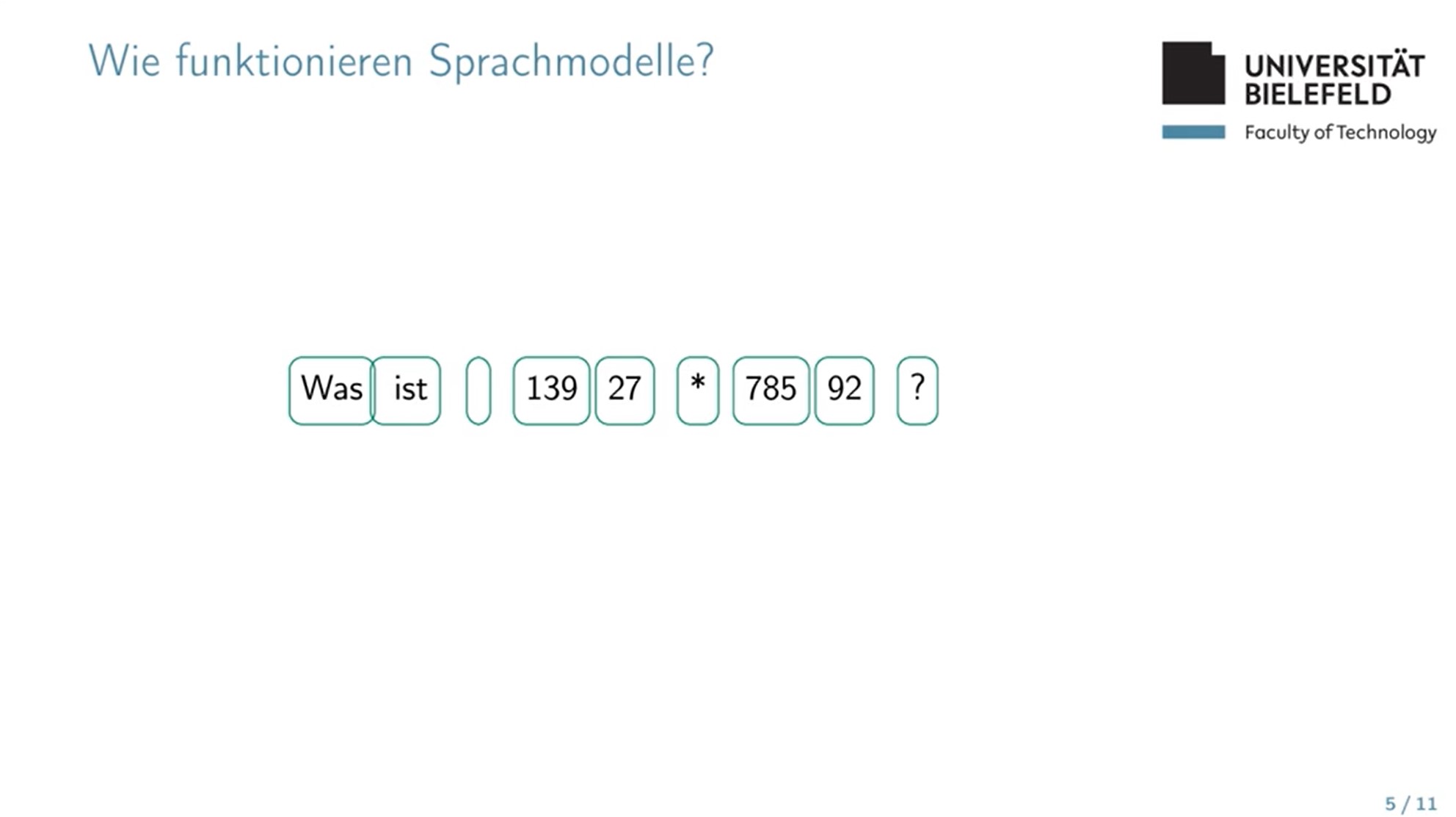
Die Technik hinter aktuellen textgenerierenden Systemen sind sog. große Sprachmodelle (engl. large language models, oder kurz LLMs). LLMs sind statistische Modelle sehr großer Textkorpora, die in der Lage sind, Texteingaben plausibel fortzusetzen. Diese Fähigkeiten erlangen LLMs durch mehrere Schritte: zunächst das „Training“ anhand Milliarden vorhandener von Menschen erstellter Texte (gescannte Bücher, Auszüge aus dem Internet usw.) und in einem weiteren Schritt durch die umfangreiche menschliche Beurteilung (nicht) wünschenswerter Ausgaben, deren entsprechend das Modell angepasst wird. Für die komfortable und vertraute Nutzung ist der Zugang zu solchen Sprachmodellen oft in Form von dialogartigen Chat-Interfaces gegeben.
Die zentrale Eigenschaft großer Sprachmodelle, von der sich sowohl deren erstaunliche Fähigkeiten als auch deren Grenzen und Probleme ableiten, ist, dass ihre Ausgaben statistisch ähnlich zu den Daten sind, mit denen sie trainiert wurden. Aussagen von LLMs sind daher meistens plausibel, aber nicht zwangsläufig korrekt. Ebenso können Ungleichgewichte in den Trainingsdaten wiedergegeben und damit verfestigt werden – wie etwa die Überrepräsentation bestimmter Sprach- und Kulturräume, im Akademischen, aber auch bestimmter Fächer, Methoden, Autor*innen usw. Umgekehrt führen potentielle Lücken und Auslassungen in den Trainingsdaten zu entsprechend unzuverlässigen Ausgaben des trainierten Modells.
Dieser Unterschied ist dabei nicht einfach zu erkennen: So ist GPT4 von OpenAI z.B. relativ zuverlässig im Berechnen von Werten der linearen Funktion 9/5x+32. Bei der Funktion 7/5x+31 versagt es dagegen regelmäßig. Warum? Die erste Funktion ist die Konversionsformel, um Grad Celsius in Grad Fahrenheit umzurechnen. Dementsprechend finden sich im Internet - und damit in den Trainingsdaten von GPT4 - viele Beispiele und Werte dieser Funktion; nicht aber der (beliebig gewählten) anderen.
Da Sprachmodelle keine Metakognition über die Inhalte dessen, was sie „wissen“ und ausgeben, betreiben können, sind sie auch nicht in der Lage, selbst zu erkennen, wenn sie zu einer Frage nichts wissen: Eine Antwort wird stets erfolgen und es bleibt den Nutzenden überlassen zu erkennen, ob sie sinnvoll ist oder nicht. Durch das oben erwähnte „Finetuning“ der Modelle durch menschliche Beurteilung und Anpassungsmaßnahmen versuchen die Hersteller von LLMs zudem die Wiedergabe toxischer (z.B. rassistischer, sexistischer oder anderweitig menschenverachtender) Inhalte, wie sie in den dem Internet entnommenen Trainingsdaten vorkommen, zu verhindern, was inzwischen besser, aber beileibe nicht immer gelingt.
Bei der Einschätzung der Fähigkeiten und Risiken von LLMs spielt also das Bewusstsein über die Daten, mit denen sie trainiert werden, eine große Rolle. Zwar halten die Hersteller die exakte Zusammensetzung der Trainingsdaten ihrer Sprachmodelle geheim, aber als Faustregel ist es hilfreich, sich als Benutzer*in Gedanken dazu zu machen, wie gut oder schlecht, einseitig oder vielseitig der Fachbereich, zu dem man ein LLM befragt, tendenziell im Internet repräsentiert ist.
- Recht
Bei der Nutzung generativer KI-Werkzeuge (inklusive BIKI) gibt es einige rechtliche Hinweise zu beachten. Insbesondere bitten wir Sie, keine personenbezogenen oder urheberrechtlich geschützten Daten in diese Systeme einzugeben/hochzuladen. Beim Einsatz in Studium und Lehre sind zusätzlich ggf. prüfungsrechtliche Aspekte zu beachten, für die wir Sie auf die entsprechende Informationsseite des Justiziariats Studium & Lehre verweisen.
- Gute wissenschaftliche Praxis
Der oben erwähnte Hinweis, dass die Ausgaben generativer KI-Werkzeuge stets auf Richtigkeit und Angemessenheit geprüft werden müssen, ist nicht nur pragmatisch erforderlich, um diese Werkzeuge sinnvoll zu nutzen, sondern leitet sich auch unmittelbar aus der Verpflichtung unserer Universität und ihrer Angehörigen zur guten wissenschaftlichen Praxis ab. Die Leitlinien der Universität Bielefeld zur Sicherung guter wissenschaftlicher Praxis finden sich hier.
- Vermenschlichung
Die bewusste und unbewusste Zuschreibung menschlicher Attribute für Systeme, die mit ihren Nutzer*innen in natürlicher Sprache interagieren können, ist ein in Kognitions- und KI-Forschung seit Langem bekanntes Phänomen. Mit den erweiterten sprachlichen Fähigkeiten aktueller generativer KI-Systeme haben sich diese Effekte noch einmal verstärkt, was sich bereits im Vokabular niederschlägt, mit dem über diese Systeme gesprochen wird: Sie „lernen“ und „wissen“, „die KI“ „denkt“ oder „halluziniert“ gar. Solche Redeweisen legen zusammen mit der für einen generativen KI-Chatbot typischen flüssigen sprachlichen Interaktion für viele Nutzende den Schluss nahe, dass es sich dabei – mindestens in Ansätzen – um ein verstehendes, denkendes Wesen handelt. Das hat wiederum Folgen für die weitere Einschätzung dieser Systeme: Ein System, das „halluziniert“, hat vorübergehend den Wahrnehmungsbezug bzw. die Realitätshaftung verloren, besitzt diese aber im Prinzip. Dieser Aspekt kann sogar bis in rechtliche Fragen hineinreichen: So ist eine häufig vorgebrachte Rechtfertigung für die Verwendung urheberrechtlich geschützter Werke im Training großer Sprachmodelle, dass sie die Texte auf ähnliche Weise „lesen“ würden, wie menschliche Autor*innen das auch tun, ohne dass Letzteren ein urheberrechtlicher Vorwurf aus der Beeinflussung des Gelesenen auf ihr Schreiben gemacht würde.
- Umwelt
Sowohl das Training als auch der Betrieb generativer KI-Systeme sind sehr energieintensiv. So verbraucht eine Anfrage an ChatGPT etwa das Sechs- bis Zehnfache einer Google-Suche. Der aktuelle Anteil, den KI-Systeme am Gesamtenergieverbrauch von Rechenzentren haben, wird auf 10-20% geschätzt, mit steigender Tendenz (siehe hier). Im November 2024 wurde der Energieverbrauch von KI-Rechenzentren für das laufende Jahr dabei auf 261 TWh geschätzt (zum Vergleich: Der Gesamtenergieverbrauch Spaniens lag 2023 bei 245 TWh).
Generative KI-Werkzeuge sollten also nicht unüberlegt eingesetzt werden. Insbesondere empfehlen wir bei Aufgaben, die sich mit anderen Werkzeugen bereits gut und ggf. auch zuverlässiger erledigen lassen (Suchmaschinen, Rechtschreib- und Grammatikprüfung, Übersetzung etc.), diese zu bevorzugen. Für Aufgaben, bei denen Sprachmodelle eine deutliche Arbeitserleichterung darstellen könnten, sollte zudem getestet werden, ob kleinere Sprachmodelle ("GPT-mini", Llama-8b" etc.) die Aufgabe bereits hinreichend gut erledigen. In diesem Zusammenhang sei auch auf das Nachhaltigkeitsleitbild der Universität Bielefeld verwiesen.
Studium und Lehre
- Generative KI als Werkzeug in Studium und Lehre
Auf verantwortliche und reflektierte Weise eingesetzt, können generative KI-Systeme u.U. ein vielseitiges, ergänzendes Werkzeug in Studium und Lehre sein. Unsere zentralen Hinweise für die diesbezügliche Nutzung von BIKI ist in den folgenden beiden Videos (einmal für Lehrende, einmal für Studierende) zusammengefasst:
Beachten Sie, dass in diesem Video für Lehrende zuvordest auf die didaktische Perspektive eingegangen wird. Wenn Sie sich unsicher sind, was z.B. die Einschätzung der Zulässigkeit des Einsatzes generativer KI-Werkzeuge als Hilfsmittel in Ihren Prüfungen angeht, beachten Sie bitte die rechtlichen Erläuterungen des Justiziariats Studium und Lehre.
Je nach Stand Ihres Fachwissens und den Besonderheiten Ihres Faches können verschiedene Anwendungsmöglichkeiten generativer KI-Werkzeuge infrage kommen oder nicht. Zentral bleibt, dass Sie in der Lage sein müssen, den Output inhaltlich einzuschätzen, dass Sie Ihre Nutzung transparent machen und für die Inhalte der Ausgaben, mit denen Sie weiterarbeiten möchten, die Verantwortung übernehmen. Am ehesten ist das bei Nutzungsformen möglich, bei denen sich Ausgaben, die Sie als untauglich bewerten, einfach verwerfen lassen. Darunter könnte z.B. das Folgende fallen:
- Unterstützung bei der Ideengenerierung
- klar umrissenes Erzeugen von Text- oder Programmcode-Entwürfen
- Paraphrasieren oder Umschreiben eigener Textstücke
- Erzeugen von Lehrmaterial-Entwürfen, z.B.
- repetitives Übungsmaterial in Variationen
- plausible Falschantworten für Multiple-Choice-Aufgaben
- Feedback oder Korrektur-Vorschläge für eigene Texte
- zusätzliche Hilfe in der Literaturrecherche (als Impulsgeber, nicht als Datenbank)
- Roh-Übersetzungen
- Generative KI als Gegenstand der Lehre
Unabhängig davon, ob Sie generative KI-Werkzeuge in Ihrem Studium oder Ihrer Lehre selbst einsetzen, empfehlen wir Lehrenden – in gebotener Kürze – generative KI als Gegenstand der Lehre zu behandeln. Insbesondere nachdem die Universität Bielefeld Lehrenden große Freiheiten in der Regulierung des konkreten Einsatzes generativer KI-Werkzeuge lässt, ist es für eine erfolgreiche Veranstaltung wichtig sicherzustellen, dass Ihre Studierenden verstehen, was die Lernziele Ihrer Veranstaltung sind und inwiefern generative KI-Werkzeuge ihnen dabei helfen oder auch hinderlich sein könnten. Idealerweise kommen Sie dazu mit Ihren Studierenden ins Gespräch und bieten ihnen die Möglichkeit eines Austauschs. Eine proaktive Thematisierung von generativer KI in Ihrer Veranstaltung ist die beste Möglichkeit zu verhindern, dass es im Nachgang der Veranstaltung Ambivalenzen und Probleme mit der Verwendung unerlaubter Hilfsmittel gibt.
Das ZLL unterstützt Sie gerne mit seinem aktuellen Workshop- und Veranstaltungsangebot bei der Thematisierung generativer KI in Ihrer Lehre. Sie können sich aber auch unabhängig von spezifischen Formaten gerne jederzeit für eine individuelle Beratung bei uns melden (zll@uni-biefeld.de).
- Generative KI und Prüfen
Was eine prüfungsrechtliche Einschätzung der potenziellen Nutzung generativer KI-Werkzeuge in Prüfungsleistungen angeht, verweisen wir auf die Seite des Justitiariats Studium und Lehre.
Falls Sie sich als Lehrende*r Gedanken darüber machen, ob Sie Ihre Prüfungsform anpassen sollten, empfehlen wir Ihnen zunächst einmal einige Ihrer bisherigen Prüfungen oder Prüfungsfragen anhand von BIKI zu testen, um selbst ein Gefühl dafür zu entwickeln, was Sprachmodelle in Ihrem Fall leisten und was nicht. Sollten Sie dabei feststellen, dass der Umfang, in dem BIKI Ihre Fragen bearbeiten kann, zu groß ist, gibt es mehrere Optionen: Die radikalste „Lösung“ ist das Ausweichen auf Prüfungsformen, in denen generative KI-Werkzeuge nicht wirklich eingesetzt werden können, wie mündliche Prüfungen oder Closed-Book-Präsenzklausuren. In schreibintensiven Fächern und Veranstaltungen, in denen z.B. das eigenständige Verfassen von Hausarbeiten zu den zu vermittelnden Kompetenzen gehört, besteht eine solche Möglichkeit allerdings nicht. Dort wäre stattdessen darüber nachzudenken, wie die bestehende Prüfungsform angepasst werden kann. Sofern Ihre Prüfungsordnung und Modulbeschreibung dies erlaubt und Sie nicht schon bereits so arbeiten, kann es z.B. hilfreich sein, Elemente des Hausarbeitsschreibens (Themenfindung, Gliederung, Peer-Diskussionen, usw.) bereits im Semesterverlauf als Teil Ihrer Veranstaltung durchzuführen. Dadurch erhalten Sie einen Einblick in verschiedene Arbeitsstadien Ihrer Studierenden und sind tendenziell besser in der Lage einzuschätzen, ob die finale Abgabe dazu passt.
Um es Ihnen zu erleichtern, eine Quellenprüfung durchzuführen, empfehlen wir zudem (sofern das bei den in Ihrem Fach üblichen Quellen möglich ist) darauf zu bestehen, dass die Studierenden zu jeder Quelle den DOI angeben müssen. So können Sie wesentlich leichter (per Copy & Paste oder per Klick) prüfen, ob die Quelle existiert und ob ihr Inhalt dem Behaupteten entspricht.


Workshops & Fortbildungen
Workshops und Fortbildungen zu generativen KI-Werkzeugen
Für aktuelle Veranstaltung u.a. zum Thema generative KI, beachten Sie bitte auch unser aktuelles Workshop-Programm für Forschende und Lehrende, das SKILLS-Programm für Studierende und die Vortrags-Reihe bi.teach.talks!
Häufige Missverständnisse
- „Ein LLM ist eine Suchmaschine.“
Vordergründig könnte man meinen, Suchmaschinen und generative KI-Chatbots erfüllen dieselbe Funktion: Sie beantworten Anfragen ihrer Nutzenden. So abstrakt, so richtig. Im Konkreten ist es jedoch wichtig die Unterschiede zu verstehen: Suchmaschinen indizieren existierende Inhalte und Web-Ressourcen, generative KI-Chatbots erzeugen auf jede Anfrage hin jedoch neuen Text, ohne dass ein Index-Eintrag eine Quellenprüfung ermöglichen würde. Statistisch gesehen ähneln KI-generierte Texte zwar denen, auf deren Basis das System trainiert wurde, aber damit ist nicht garantiert, dass jede einzelne Antwort eines generativen KI-Systems zutreffend ist. Obendrein wird der Index, den eine Suchmaschine durchsucht, kontinuierlich aktualisiert, während Sprachmodelle ihre Textantworten nur auf Basis der Texte, mit denen sie – zu einem bestimmten Zeitpunkt in der Vergangenheit – trainiert wurden, erzeugen können. Für viele einfache Nachschlage-Aufgaben sind also „klassische“ Suchmaschinen weiterhin die zu empfehlende Methode, um an vertrauenswürdiges und aktuelles Wissen zu gelangen.
- „Ein LLM hat Zugriff auf das Internet.“
Die Sprachmodelle, auf denen generative KI-Systeme basieren, werden mit einem bestimmten Datensatz trainiert, auf Basis dessen das System dann später seine Antworten generiert. Diese enthalten zwar Teile des Internets zum Zeitpunkt des Trainings, können später aber nicht mehr aktualisiert werden. Einige generative KI-Werkzeuge bieten die zusätzliche Funktion, zum Zeitpunkt der Anfrage Webseiten abzurufen und deren Inhalt bei der Generierung des Antworttextes zu berücksichtigen (das Sprachmodell wird dann mit der ursprünglichen Anfrage zuzüglich des Inhalts der fraglichen Webseite geprompted). Insbesondere bei längeren oder interaktiven Webseiten funktioniert das allerdings nur bedingt.
- „Ein LLM kann Quellen/Belege liefern.“
Ein generatives KI-System wird auf die Frage nach Quellen oder Belegen hin zwar häufig eine Antwort geben, die auf bestimmte Quellen/Belege hinweist, diese Antwort ist aber kein tatsächliches Nachschlagen in entsprechenden Datenbanken oder Indizes, sondern durch das unterliegende Sprachmodell erzeugter Text. Entsprechend der Häufigkeit von Bezugnahmen auf die jeweilige Quelle im Trainingsmaterial kann diese Antwort zutreffend sein, ist u.U. aber auch falsch; bei selten diskutierten Fachpublikation umso eher. Einige spezielle KI-Werkzeuge sind daher an zusätzliche Datenbanken angebunden, die auf Basis davon relativ zuverlässige Antworten liefern können, viele dieser Lösungen sind aber vorrangig auf englischsprachige Publikationen aus dem MINT-Bereich ausgerichtet.
- „KI-generierte Texte können automatisch von menschlich geschriebenen Texten unterschieden werden (KI-Erkennungstools).“
Nachdem KI-generierte Texte statistisch die Texte, mit denen das KI-System trainiert wurde widerspiegeln, sind sie auch von KI-Systemen, die diese Texte statistisch analysieren, nicht zuverlässig voneinander zu unterscheiden. Vereinzelte generative KI-Werkzeuge haben zwar immer wieder idiosynkratische Elemente in ihren Outputs, die ein anderes System zu erkennen lernen könnte, allerdings können sich diese über die Zeit ändern und darüber hinaus sind sowohl die Falsch-Negativ als auch Falsch-Positiv-Raten dieser „Erkennungstools“ sehr hoch. Besonders brisant dabei: Insbesondere der Sprachgebrauch von Nichtmuttersprachlern und sprachlichen Minderheiten wird häufig fälschlicherweise als KI-generiert markiert.
Von der Verwendung von KI-Erkennungstools raten wir daher prinzipiell ab.
- „LLMs werden vollautomatisch trainiert.“
Oft hört man, die Fortschritte generativer KI-Technologien in der jüngeren Zeit wären zuvorderst der Kombination des Sammelns großer Datenmengen im Internet und der gestiegenen Rechenkapazität moderner Rechenzentren zuzuschreiben. Dabei fällt hintenüber, dass auch in moderner KI sehr viel Handarbeit steckt: Nicht nur wurden die Texte, auf Basis derer Sprachmodelle trainiert werden von Menschen geschrieben, die Trainingsdatensätze müssen von Menschen zusammengetragen und nach unangemessenen Inhalten durchsiebt werden. Nach diesem Trainingsschritt wird in weiterer Handarbeit das „Fine-Tuning“ des Modells durchgeführt, bei dem Menschen dem Modell „abtrainieren“ bestimmte unerwünschte Antworten zu geben. Die Bedingungen unter denen Klickarbeiter*innen diese Arbeiten durchführen, sollen dabei nicht unerwähnt bleiben.
- „Falschinformation (sog. Halluzinationen), Toxizität usw. sind Probleme, die sich mit dem Einsatz von mehr Daten und mehr Rechenzeit von selbst erledigen werden.“
Große Teile des Pessimismus sowie Optimismus gegenüber generativer KI beziehen sich nicht nur darauf, was derzeit verfügbare Systeme können, sondern insbesondere darauf, was zukünftige Systeme möglicherweise können könnten. Dabei wird häufig angenommen, dass die Probleme gegenwärtiger Systeme sich durch „Skalierung“ der derzeitigen technischen Ansätze – also durch hinzuziehen immer größerer Datenmengen und Training größerer Modelle – mehr oder weniger von selbst erledigen werden. Aus rein technischer Sicht besteht dabei aktuell unter Forschenden keine Einigkeit darüber, was mit der Skalierung derzeitiger Methoden erreicht werden kann. Im Hinblick darauf, dass z.B. die Sammlung und Bearbeitung immer größerer Datensätze nicht vollautomatisch passiert, sondern manuelle Schritte beinhaltet, deren Aufwand (mindestens) mit der Größe des Datensatzes skaliert, sind diesem Ansatz jedoch natürliche Grenzen gesetzt. So konnte u.a. gezeigt werden, dass größere, von anderweitig auf gleiche Weise erstellten Datensätzen anteilig eine größere Zahl toxischer Inhalte beinhalten.